Hello, learners welcome to The Engineering Projects. We are working on MATLAB, and in this tutorial, you are going to learn a lot about matrices in MATLAB. We are going to learn them from scratch, but we will avoid unnecessary details about the topic. So, without wasting time, have a look at the topics that you will learn in detail.
What is an array?
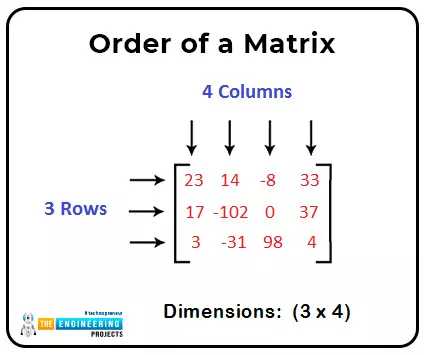
What is the matrix?
How can we declare a matrix in MATLAB?
What are the different types of matrices?
Can we find the unknown values of two equal matrices?
How can we solve the simultaneous equation in MATLAB?
What is an Array?
In this world of technology, the use of data is everywhere, and therefore, we can say there is a need for arrays in every field. You will find the reason soon. But before this, look at the introduction of a ...
Thank you for joining us for yet another session of this series on Raspberry Pi programming. In the previous tutorial, we built a motion sensor-based security system with an alarm. Additionally, we discovered how to use Twilio to notify the administrator whenever an alarm is triggered. However, in this tutorial, we'll learn how to build a stop motion film system using raspberry pi 4.
What you will make
With a Raspberry Pi, Py, and a pi-camera module to capture images, you can create a stop-motion animated video. In addition, we'll learn about the various kinds of stop motion systems and their advantages and disadvantages.
The possibilities are endless when it comes to using LEGO to create animations!
...
Hi friends, today we are going to learn a good technique to run multi outputs in sequence. In another word, when we have some output that is repeatedly run in sequence. In the normal or conventional technique of programming we deal with them individually or one by one which takes more effort in programming and much space of memory. So instead we can use a new technique to trigger these outputs in sequence using one instruction which will save the effort of programming and space of memory. In this article, we are going to introduce how to implement sequencer output instruction. And practice some examples with the simulator as usual. Before starting the article, we need to mention that, some controllers like Allen Bradley have sequencer output instruction and some has not like Siemens. So we ...
Thank you for joining us for yet another session of this series on Raspberry Pi programming. In the preceding tutorial, we integrated a real-time clock with our raspberry pi four and used it to build a digital clock. However, In this tutorial, we will construct your personal Twitter bot using Tweepy, a Py framework for querying the Twitter application programming interface.
You will construct a Response to mentions robot that will post a response to everybody's tweet mentioning it with a certain keyword.
The response will be a photo we will make and put any text over it. This message is a quote you will acquire from a 3rd application programming interface. Finally, we will look at the benefits and drawbacks of bots.
This is what it looks like:
...
Introduction
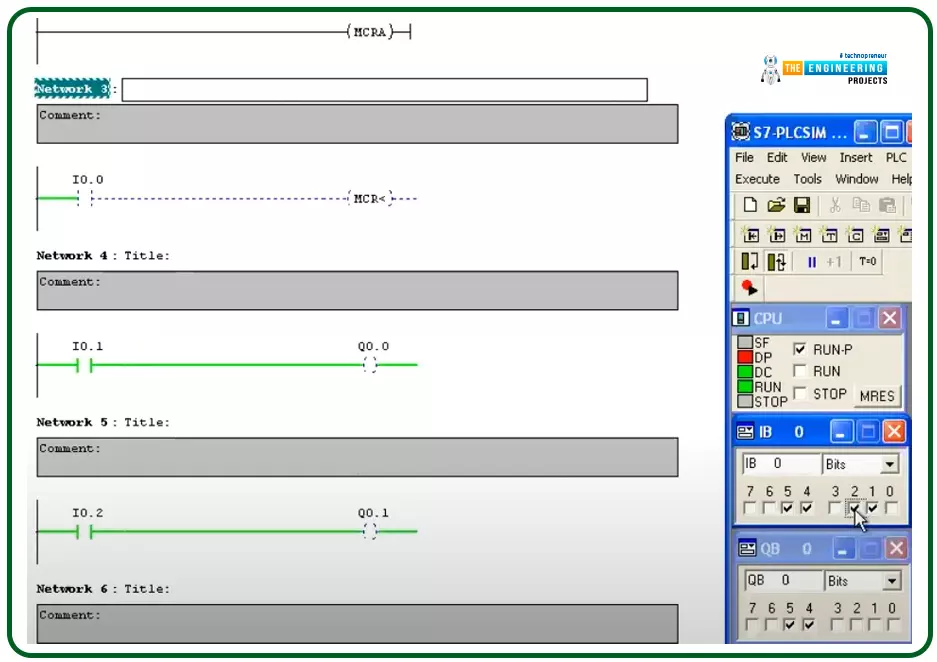
Hello friends, I hope you are doing very well. Today we are going to learn and practice the master control reset (MCR)! So what is that MCR? Well! This is a tool you might use to control a group of devices with one push button for performing fast emergency responses with one click for a group of devices in one zone. In another word, you divide the program into zones and put this zone between a master control to control their operation as one unit by one contact. This technique is useful for applying emergence stops and also protecting some equipment by applying a safety restriction to not operate when that condition is in effect.
The concept of the master control reset (MCR)
Figure 1 shows the master control relay in a ladder logic showing a couple of rungs between the ma ...
Hey learners! Welcome to another exciting lecture in this series of signals and systems. We are learning about the transform in signals and systems, and in the previous lectures, we have seen a bulk of information about the Laplace transform. If you know the previous concepts of signal and system, then this lecture will be super easy for you to learn, but if your concepts are not clear, do not worry because we will revise all the basic information from scratch for our new readers. So, without wasting time, have a look at the topics of today.
What is z transform?
What is the region of convergence of z transform?
What are some of the important properties of the region of convergence?
How to solve the z transform?
What is an example of the z transform in MATLAB?
What are the methods fo ...
Thank you for joining us for yet another session of this series on Raspberry Pi programming. In the preceding tutorial, we created a pi-hole ad blocker for our home network using raspberry pi 4. We also learned how to install pi-hole on raspberry pi four and how to access it in any way with other devices. This tutorial will implement a speech recognition system using raspberry pi and use it in our project. First, we will learn the fundamentals of speech recognition, and then we will build a game that uses the user's voice to play it and discover how it all works with a speech recognition package.
Here, you'll learn:
The basics of voice recognition
On PyPI, what packages may be found?
Utilize the SpeechRecognition package with a wide range ...
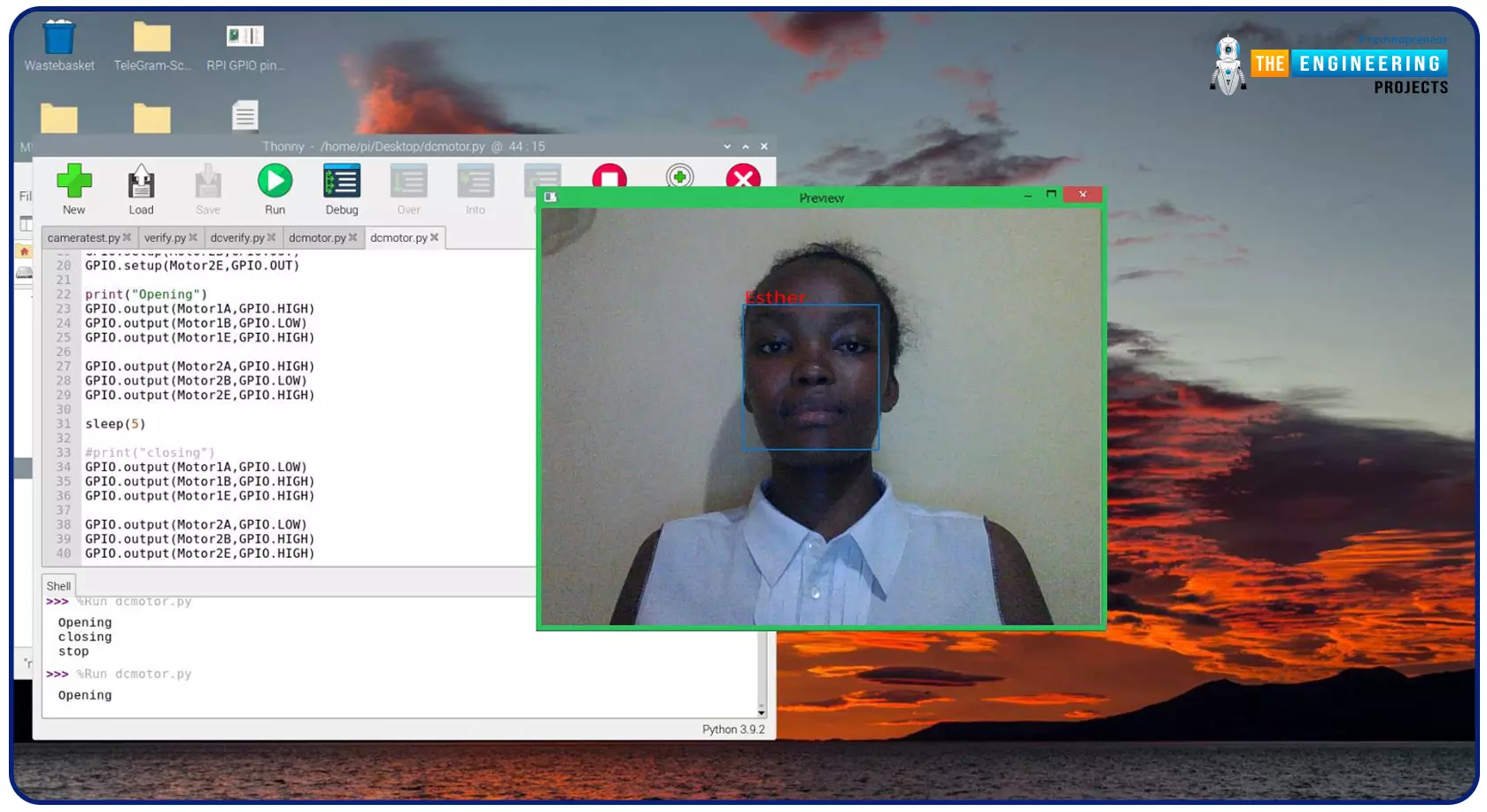
Greeting, and welcome to the next tutorial of our raspberry programming tutorial. In the previous tutorial, we learned how to build a smart attendance system using an RFID card reader, which we used to sign in students in attendance in a class. When it comes to building a face-recognition program on a Raspberry Pi, this tutorial will show you how. Two Python programs will be used in the lesson, one of which is a Training program that analyzes a collection of photographs of a certain individual and generates a dataset. (YML File). The Recognizer application uses the YML script to detect a face and afterward utters the person's name when the face is detected.
Components
Raspberry Pi
Breadboard
L293 or SN755410 motor driver chip
Jumper wir ...
Welcome to the next tutorial of our Raspberry Pi programming course. Our previous tutorial taught us to how to print from a Raspberry pi. We also discussed some libraries to create a print server in our raspberry pi. We will learn how to take screenshots on Raspberry Pi using a few different methods in this lesson. We will also look at how to take snapshots on our Raspberry Pi using SSH remotely.
Why should you read this article?
This article will assist you when working with projects that require snapshots for documenting your work, sharing, or generating tutorials.
So, let us begin.
Screenshots are said to be the essential items on the internet today. And if you have seen these screenshots in tutorial videos or even used them in regular commu ...
Welcome to the next tutorial of our Raspberry Pi programming course. Our previous tutorial taught us to make a button-controlled "music box" that plays different sounds depending on which buttons are pressed. In this lesson, we will configure our raspberry pi for voice control.
What will you learn?
Like the Amazon Echo, voice-activated gadgets are becoming increasingly popular, but you can also construct your own with a Raspberry, a cheap USB mic, and some appropriate software. Simply speaking to your Raspberry Pi will allow you to search YouTube, view websites, activate applications, and even answer inquiries.
What will you need?
Because the Raspberry Pi lacks a soundcard or audio port, this project requires a USB microphone or a camera with a ...