In today's digital age, remote workers are on the frontlines of an invisible war, battling unseen cyber threats. As they maneuver through the complex terrain of remote work environments, they're confronted with potential hazards at every turn.
From a compromised network and data breach to phishing attacks, remote workers are tasked with safeguarding the organization's digital fort.
Building a cybersecurity culture
The remote workforce is instrumental in building a cybersecurity culture where everyone becomes their own expert, advocating for security measures and promptly reporting suspiciou ...
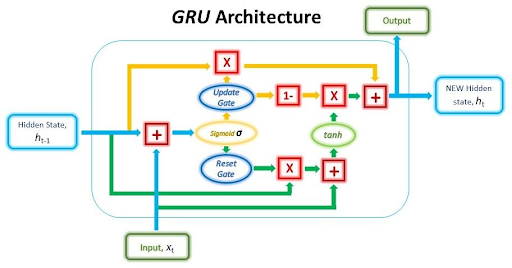
Hello! I hope you are doing great. Today, we will talk about another modern neural network named gated recurrent units. It is a type of recurrent neural network (RNN) architecture but is designed to deal with some limitations of the architecture so it is a better version of these. We know that modern neural networks are designed to deal with the current applications of real life; therefore, understanding these networks has a great scope. There is a relationship between gated recurrent units and Long Short-Term Memory (LSTM) networks, which has also been discussed before in this series. Hence, ...
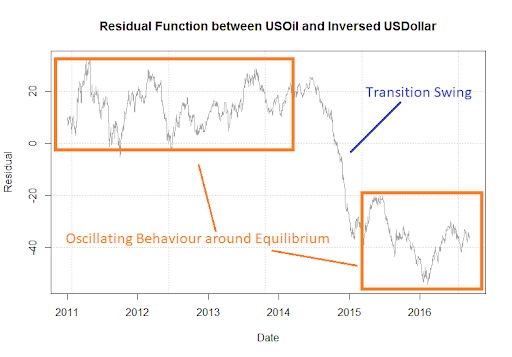
Hey readers! Welcome to the next lecture on neural networks. We are learning about modern neural networks, and today we will see the details of residual networks. Deep learning has provided us with remarkable achievements in recent years, and residual learning is one such output. This neural network has revolutionized the design and training process of the deep neural network for image recognition. This is the reason why we will discuss the introduction and all the content regarding the changes these network has made in the field of computer vision.In this article, we will discuss the basic in ...
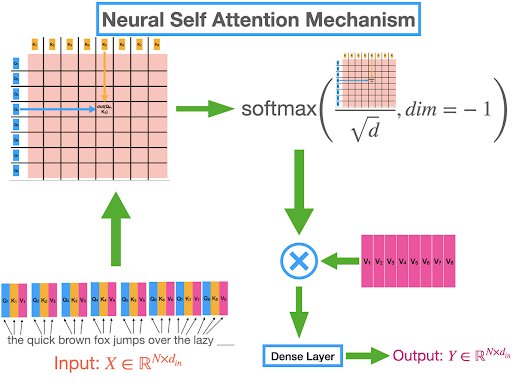
Deep learning is an important subfield of artificial intelligence and we have been working on the modern neural network in our previous tutorials. Today, we are learning the transformer architecture neural network in deep learning. These neural networks have been gaining popularity because they have been used in multiple fields of artificial intelligence and related applications.
In this article, we will discuss the basic introduction of TNNs and will learn about the encoder and decoders in the structure of TNNs. After that, we will see some important features and applications of this neu ...
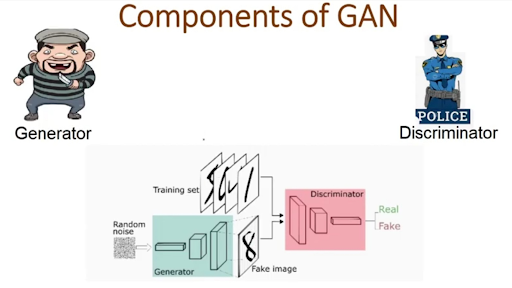
Deep learning has applications in multiple industries, and this has made it an important and attractive topic for researchers. The interest of researchers has resulted in multiple types of neural networks we have been discussing in this series so far. Today, we are talking about generative advertising neural networks (GAN). This algorithm performs the unsupervised learning task and is used in different fields of life such as education, medicine, computer vision, natural language processing (NLP), etc.
In this article, we will discuss the basic introduction of GAN and will see the working mec ...
Hi readers! I hope you are doing great. We are learning about modern neural networks in deep learning, and in the previous lecture, we saw the capsule neural networks that work with the help of a group of neurons in the form of capsules. Today we will discuss the graph neural network in detail.
Graph neural networks are one of the most basic and trending networks, and a lot of research has been done on them. As a result, there are multiple types of GNNs, and the architecture of these networks is a little bit more complex than the other networks. We will start the discussion with the introduct ...







 Getting Started Guide
Getting Started Guide
 Help Center
Help Center
 Contact us
Contact us
 Doist Blog
Doist Blog
 Privacy
Privacy
 Security
Security
 Terms of Service
Terms of Service
 What's new: Channel Descriptions
What's new: Channel Descriptions



 1 user
1 user








 2
2




















 20K
20K 900
900 900
900 20K
20K



