Hi readers! I hope you are doing great. We are learning about modern neural networks in deep learning, and in the previous lecture, we saw the capsule neural networks that work with the help of a group of neurons in the form of capsules. Today we will discuss the graph neural network in detail.
Graph neural networks are one of the most basic and trending networks, and a lot of research has been done on them. As a result, there are multiple types of GNNs, and the architecture of these networks is a little bit more complex than the other networks. We will start the discussion with the introduction of GNN.
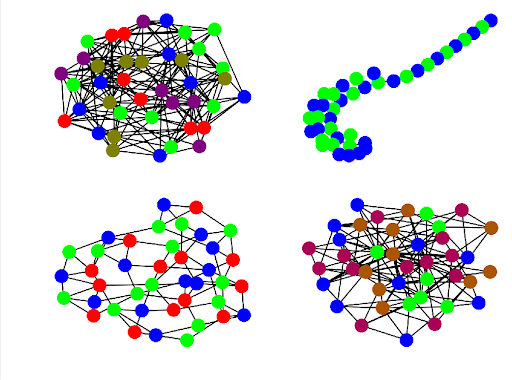
Introduction to Graph Neural Networks
The work on graphical neural networks started in the 2000s when researchers explored graph-based semi-supervised learning in the neural network. The ...
Hey pupil! Welcome to the next lecture on modern neural networks. I hope you are doing great. In the previous lecture, we saw the EffcientNet neural network, which is a convolutional Neural Network (CNN), and its properties. Today, we are talking about another CNN network called the capsule neural network, or CapsNets. These networks were introduced to provide the capsulation in CNNs to provide better functionalities.
In this article, we will start with the introduction of the capsule neural network. After that, we will compare these with the traditional convolutional neural networks and learn some basic applications of these networks. So, let’s start learning.
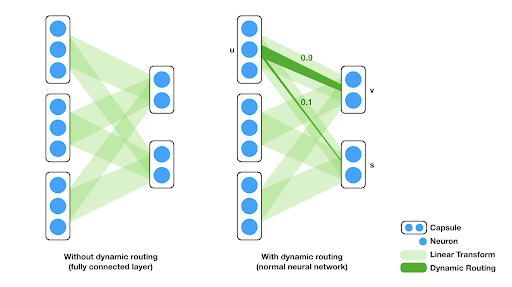
Introduction to Capsule Neural Networks
Capsule neural networks are a type of artificial neural network that was introduc ...
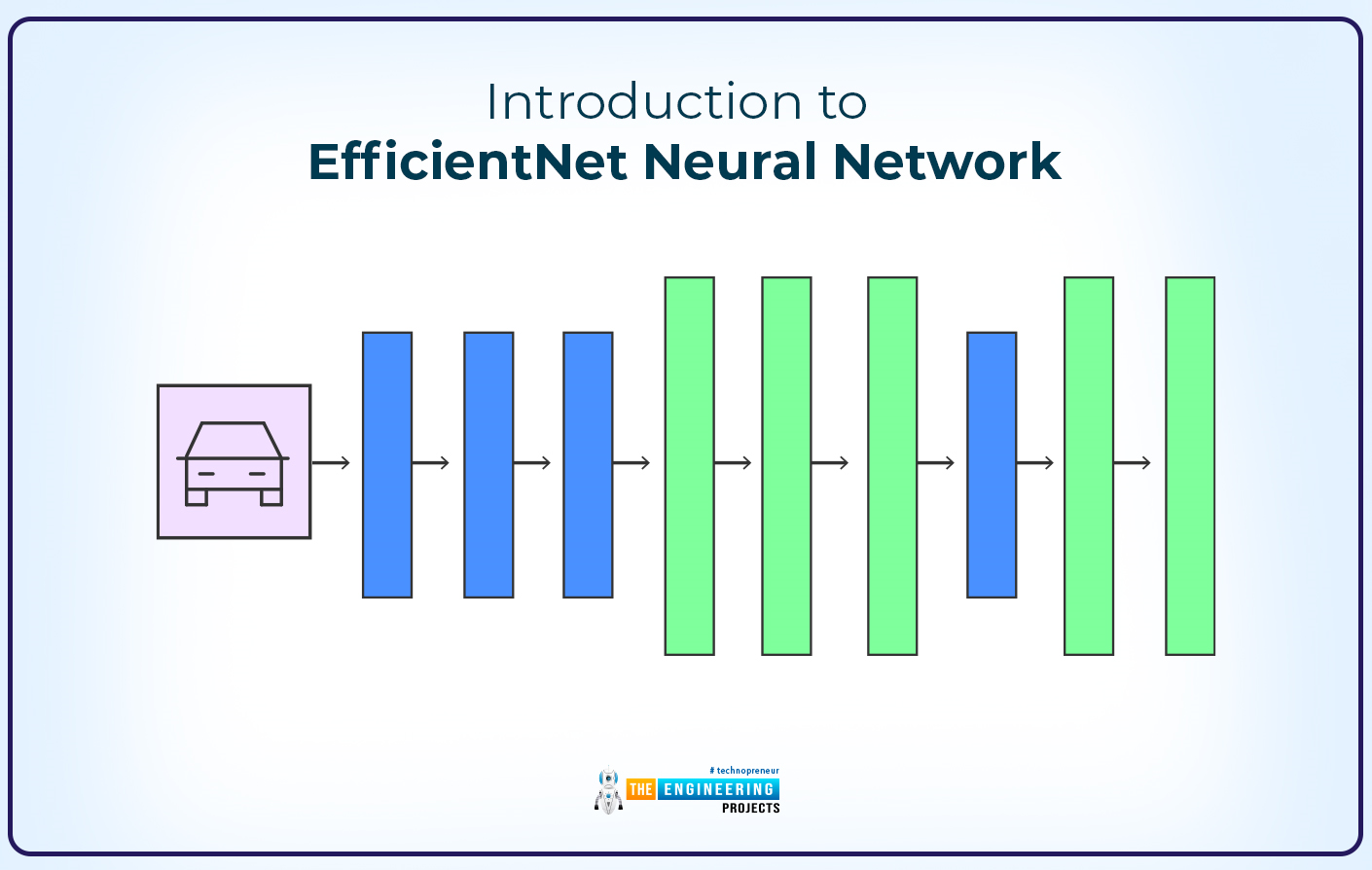
Hi learners! I hope you are having a good day. In the previous lecture, we saw Kohonen’s neural network, which is a modern type of neural network. We know that modern neural networks are playing a crucial role in maintaining the workings of multiple industries at a higher level. Today we are talking about another neural network named EfficientNet. It is not only a single neural network but a set of different networks that work alike and have the same principles but have their own specialized workings as well.
EfficentNet is providing groundbreaking innovations in the complex fields of deep learning and computer vision. It makes these fields more accessible and, therefore, enhances their range of practical applications. We will start with the introduction, and then we will share some usefu ...
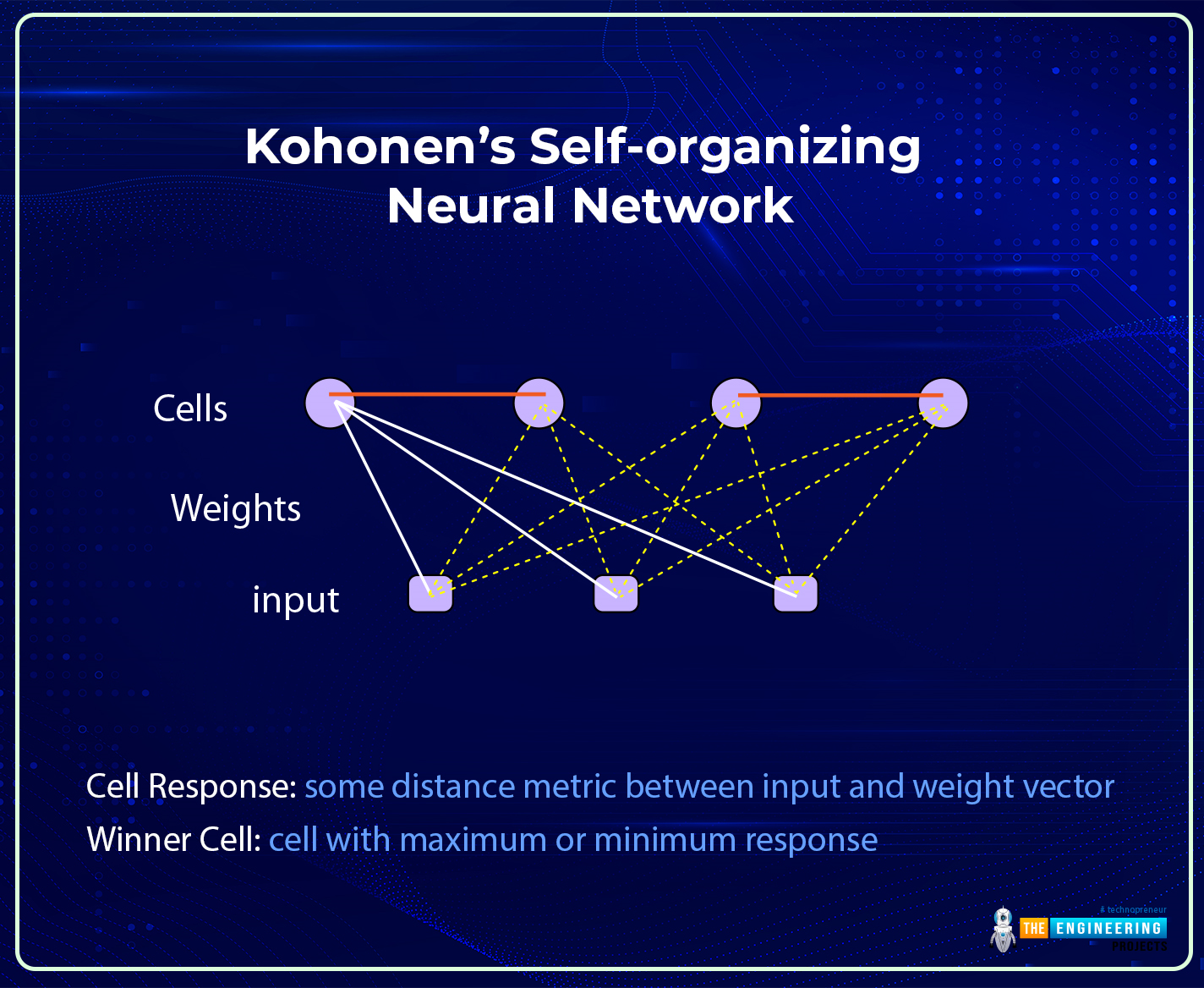
Hi there! I hope you are having a great day. The success of the field of deep learning is due to its complex and advanced neural networks. These networks can be broadly divided into traditional and modern neural networks. We have seen the details of traditional neural networks, and in the previous session, the basic introduction of modern neural networks and the details of their features were discussed. Today, we will talk about one of the most famous modern neural networks, the Kohonen Self-Organized Neural Network.
Modern neural networks are more organized and developed than traditional neural networks, but that does not make traditional neural networks less efficient than modern ones. All the networks are introduced for specific tasks, and this is one of the main reasons behind t ...
Hi pals! Welcome to the next deep learning tutorial, where we are at the exciting stage of TensorFlow. In the last tutorial, we just installed the TensorFlow library with the help of Anaconda, and we saw all the procedures step by step. We saw all the prerequisites and understood how you can follow the best procedure to download and install TensorFlow successfully without any trouble. If you have done all the steps, then you might be interested in knowing the basics of TensorFlow. No matter if you are a beginner or have knowledge about TensorFlow, this lecture will be equally beneficial for all of you because there is some important and interesting information that not all people know. So, have a look at the topics that will be discussed with you in just a bit.
What is a tensor?
What are ...
Hello Peeps! Welcome to the next lecture on deep learning, where we are discussing TensorFlow in detail. You have seen why we have chosen TensorFlow for this course, and we have read a lot about the working mechanism, programming languages, and advantages of using TensorFlow instead of other libraries. Instead of using the other options for the same purpose, we have seen several reasons to use TensorFlow. Because of the latest work on the library for more improvement and better results, it's now time to learn the specifics of TensorFlow installation. But before this, you have to check the list of the concepts that will be cleared today:
Is Installation of TensorFlow Difficult?
The simple and to-the-point answer to this question is, the installation is easy and usually does not require ...
Hey learners! Welcome to the new tutorial on deep learning, where we are going deep into the learning of the best platform for deep learning, which is TensorFlow. Let me give you a reminder that we have studied the need for libraries of deep learning. There are several that work well when we want to work with amazing deep-learning procedures. In today’s lecture, you are going to know the exact reasons why we chose TensorFlow for our tutorial. Yet, first of all, it is better to present the list of topics that you will learn today:
Why do we use TensorFlow with deep learning?
What are some helpful features of this library?
How can you understand the mechanism of TensorFlow?
Show the light towards the architecture, and components of the TensorFlow.
In how many phases you can complete t ...
Hey buddies! Welcome to the next tutorial on deep learning, in which you are about to acquire knowledge related to Python. This is going to be very interesting because the connection between these two is easy and useful. In the last lecture, we had an eye on the latest and trendiest deep learning algorithms, and therefore, I think you are ready to take the next step towards the implementation of the information that I shared with you. To help you make up your mind about the topics of today, I have made a list for you that will surely be useful for you to understand what we are going to do today.
How do you introduce the Python programming language to a deep learning developer?
How is Python useful for deep learning training in different ways?
Do Python provide the useful frameworks for ...
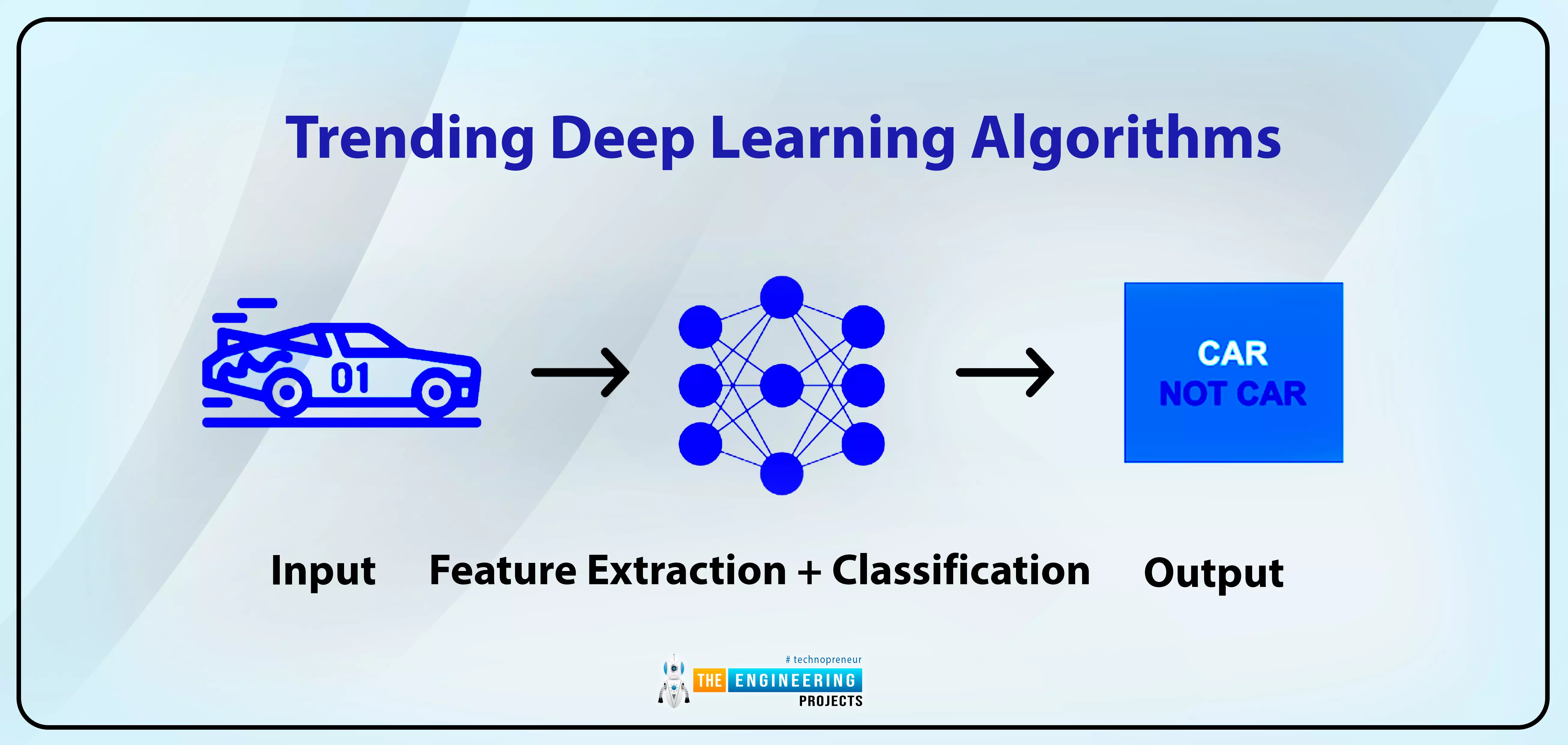
Hello pupils! Welcome to the following lecture on deep learning. As we move forward, we are learning about many of the latest and trendiest tools and techniques, and this course is becoming more interesting. In the previous lecture, you saw some important frameworks in deep learning, and this time, I am here to introduce you to some fantastic algorithms of deep learning that are not only important to understand before going into the practical implementation of the deep learning frameworks but are also interesting to understand the applications of deep learning and related fields. So, get ready to learn the magical algorithms that are making deep learning so effective and cool. Yet before going into details, let me discuss the questions for which we are trying to find answers.
How does dee ...
Hello peeps. Welcome to the next tutorial on deep learning. You have learned about the neural network, and it was an interesting way to compare different types of neural networks. Now, we are talking about deep learning frameworks. In the previous sessions, we introduced you to some important frameworks to let you know about the connection of different entities, but at this level, it is not enough. We are telling you in detail about all types of frameworks that are in style because of their latest features. So before we start, have a look at the list of concepts that will be covered today:
Introduction to the frameworks of deep learning.
Why do we require frameworks in deep learning?
What are some important deep learning frameworks?
What is TensorFlow and for which purpose of using Ten ...