

Hello! I hope you are doing great. Today, we will talk about another modern neural network named gated recurrent units. It is a type of recurrent neural network (RNN) architecture but is designed to deal with some limitations of the architecture so it is a better version of these. We know that modern neural networks are designed to deal with the current applications of real life; therefore, understanding these networks has a great scope. There is a relationship between gated recurrent units and Long Short-Term Memory (LSTM) networks, which has also been discussed before in this series. Hence, I highly recommend you read these two articles so you may have a quick understanding of the concepts.
In this article, we will discuss the basic introduction of gated recurrent units. It is better to define it by making the relations between LSTM and RNN. After that, we will show you the sigmoid function and its example because it is used in the calculations of the architecture of the GRU. We will discuss the components of GRU and the working of these components. In the end, we will have a glance at the practical applications of GRU. Let’s move towards the first section.

What is a Gated Recurrent Unit?
The gated recurrent unit is also known as the GRU and these are the types of RNN that are designed for processes that involve sequential data. One example of such tasks is natural language processing (NLP). These are variations of long short-term memory (LSTM) networks, but they have an upgraded mechanism and are therefore designed to provide easy implementation and working features.
The GRU was introduced in 2014 by Kyunghyun Cho, Bart van Merriënboer, Dzmitry Bahdanau, and Yoshua Bengio. They have written the paper with the title "Learning Phrase Representations using Gated Recurrent Units." This paper gained fame because it was published at the 31st International Conference on Machine Learning (ICML 2014). This mechanism was successful because it was lightweight and easy to handle. Soon, it became the most popular neural network for complex tasks.
What is the Sigmoid Function in GRU?
The sigmoid function in neural networks is the non-linear activation function that deals with values between 0 and 1 as input. It is commonly used in recurrent networks and in the case of GRU, it is used in both components. There are different sigmoid functions and among these, the most common is the sigmoid curve or logistic curve.
Mathematically, it is denoted as: f(x) = 1 / (1 + e^(-x))
Here,
f(x)= Output of the function
x = Input value
When the x increases from -∞ to +∞, the range increases from 0 to 1.

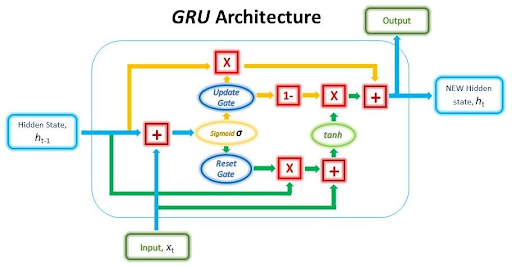
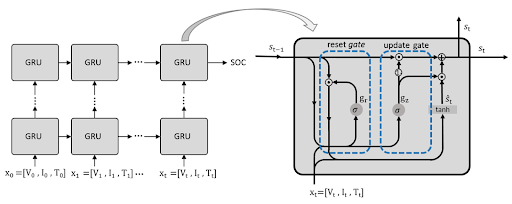
Architecture of GRU
The basic mechanism for the GRU is simple and approaches the data in a better way. This gating mechanism selectively updates the hidden state of the network and this happens at every step. In this way, the information coming into the network and going out of it is easily controlled. There are two basic mechanisms of gating in the GRU:
- Update Gate (z)
- Reset Gate (r)
The following is a detailed description of each of them:
Update Gate (z)
The update gate controls the flow of the precious state. It shows how much information from the previous state has to be retained. Moreover, it also provides information about the update and the new information required for the best output. In this way, it has the details of the previous and current steps in the working of the GRU. It is denoted by the letter z and mathematically, the update gate is denoted as:
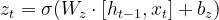
Here,
W(z) = weight matrix for the update gate
ℎ(t−1)= Previous hidden state
x(t)= Input at time step t
σ = Sigmoid activation function
Reset Gate (r)
The resent gate determines the part of the previous hidden state that must be reset or forgotten. Moreover, it also provides information about the part of the information that must be passed to the new candidate state. It is denoted by "r,” and mathematically,

Here,
r(t) = Reset gate at the time step
W(r) = Weight matrix for the reset gate
h(t−1) = Previous hidden state
x(t)= Input at time step
σ = Sigmoid activation function.
Once both of these are calculated, the GRU then apply the calculations for the candidate state h(t). The “h” in the symbol has a tilde at it. Mathematically, the candidate state is denoted as:
ht=tanh(Wh⋅[rt⋅ht−1,xt]+bh)
When these calculations are done, the results obtained are shown with the help of this equation:
ht=(1−zt)⋅ht−1+zth~t
These calculations are used in different ways to provide the required information to minimize the complexity of the gated recurrent unit.
Working of Gated Recurrent Unit
The gated recurrent unit works by processing the sequential data, then capturing dependencies over time and in the end, making predictions. In some cases, it also generates the sequences. The basic purpose of this process is to address the vanishing gradient and, as a result, improve the overall modelling of long-range dependencies. The following is the basic introduction to each step performed through the gated recurrent unit functionalities:
Initialisation of GRU
In the first step, the hidden state h0 is initialized with a fixed value. Usually, this initial value is zero. This step does not involve any proper processing.
Processing in GRU
This is the main step and here, the calculations of the update gate and reset gate are carried out. This step requires a lot of time, and if everything goes well, the flow of information results in a better output than the previous one. The step-by-step calculations are important here and every output becomes the input of the next iteration. The reason behind the importance of some steps in processing is that they are used to minimize the problem of vanishing gradients. Therefore, GRU is considered better than traditional recurrent networks.
Hidden State Update
Once the processing is done, the initial results are updated based on the results of these processes. This step involves the combination of the previous hidden state and the processed output.
Difference Between GRU and LSTM
Since the beginning of this lecture, we have mentioned that GRU is better than LSTM. Recall that long short-term memory is a type of recurrent network that possesses a cell state to maintain information across time. This neural network is effective because it can handle long-term dependencies. Here are the key differences between LSTM and GRU:
Architecture Complexity of the Networks
The GRU has a relatively simpler architecture than the LSTM. The GRU has two gates and involves the candidate state. It is computationally less intensive than the LSTM.
On the other hand, the LSTM has three states named:
- Input gate
- Forget gate
- Output gate
In addition to this, it has a cell state to complete the process of calculations. This requires a complex computational mechanism.
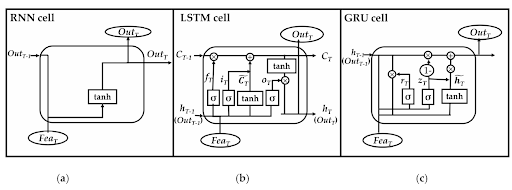
Gate Structure of GRU and LSTM
The gate structures of both of these are different. In GRU, the update gate is responsible for the information flow from the current candidate state to the previous hidden state. In this network, the reset gate specifies the data to be forgotten from the previous hidden state.
On the other hand, the LSTM requires the involvement of the forget gate to control the data to be retained in the cell state. The input gates are responsible for the flow of new information into the cell state. The hidden state also requires the help of an output gate to get information from the cell state.
Training Time
The simple structure of GRU is responsible for the shorter training time of the data. It requires fewer parameters for working and processing as compared to LSTM. A high processing mechanism and more parameters are required for the LSTM to provide the expected results.
Performance of GRU and LSTM
The performance of these neural networks depends on different parameters and the type of task required by the users. In some cases, the GRU performs better and sometimes the LSTM is more efficient. If we compare by keeping computation time and complexity in mind, GRU has a better output than LSTM.
Memory Maintainance
The GRU does not have any separate cell state; therefore, it does not explicitly maintain the memory for long sequences. Therefore, it is a better choice for the short-term dependencies.
On the other hand, LSTM has a separate cell state and can maintain the long-term dependencies in a better way. This is the reason that LSTM is more suitable for such types of tasks. Hence, the memory management of these two networks is different and they are used in different types of processes for calculations.
Applications of Gated Recurrent Unit
The gated recurrent unit is a relatively newer neural network in modern networks. But, because of the easy working principle and better results, this is used extensively in different fields. Here are some simple and popular examples of the applications of GRU:
Natural Language Processing
The basic and most important example of an application is NLP. It can be used to generate, understand, and create human-like language. Here are some examples to understand this:
The GRU can effectively capture and understand the meaning of words in a sentence and is a useful tool for machine translation that can work between different languages.
The GRU is used as a tool for text summarization. It understands the meaning of words in the text and can summarize large paragraphs and other pieces of text effectively.
The understanding of the text makes it suitable for the question-answering sessions. It can reply like a human and produce accurate replies to queries.
Speech Recognition with GRU
The GRU does not only understand the text but is also a useful tool for understanding and working on the patterns and words of the speech. They can handle the complexities of spoken languages and are used in different fields for real-time speech recognition. The GRU is the interface between humans and machines. These can convert the voice into text that a machine can understand and work according to the instructions.
Security measures with GRU
With the advancement of technology, different types of fraud and crimes are becoming more common than at any other time. The GRU is a useful technique to deal with such issues. Some practical examples in this regard are given below:
- GRU is used in financial transactions to identify patterns and detect fraud and other suspicious activities to stop online fraud.
- The networks are analyzed deeply with the help of GRU to identify malicious activities and retain the chance of any harmful process, such as a cyberattack.
Bottom Line
Today, we have learned about gated recurrent units. These are modern neural networks that have a relatively simple structure and provide better performance. These are the types of recurrent neural networks that are considered a better version of long short-term neural networks. Therefore, we have discussed the structure and processing steps in detail and in the end, we compared the GRU with the LSTM to understand the purpose of using it and to get an idea about the advantages of these neural networks. In the end, we saw practical examples where the GRU is used for better performance. I hope you like the content and if you have any questions regarding the topic, you can ask them in the comment section.
